Dispatch #17 - Cyber Territories

This week's Dispatch turns around major questions that decision-makers in media can no longer postpone: on whose terms does AI enter journalism, and who is paid when it does. The technology is already inside the newsrooms. What remains to be settled are the rules of disclosure, the price of access, and the shape of a business model that can support both sides.
Four themes organise this edition.
The first concerns authorship and the duty to disclose.
The second concerns the legal aspects, where more than a hundred copyright actions, new European rules, and a fresh legal argument about how training data was obtained are bringing more equilibrium.
The third concerns innovation, where publishers and agencies build AI products on their own archives, their own sources and their own editorial standards.
The fourth concerns the economics underneath all of it, where the model of the referral click that financed the open web and its advertising model, is about to retire.
These themes meet at the gateway between readers and the journalism that informs them, and the engine that powers most of the old internet, Google, occupies much of that gateway.
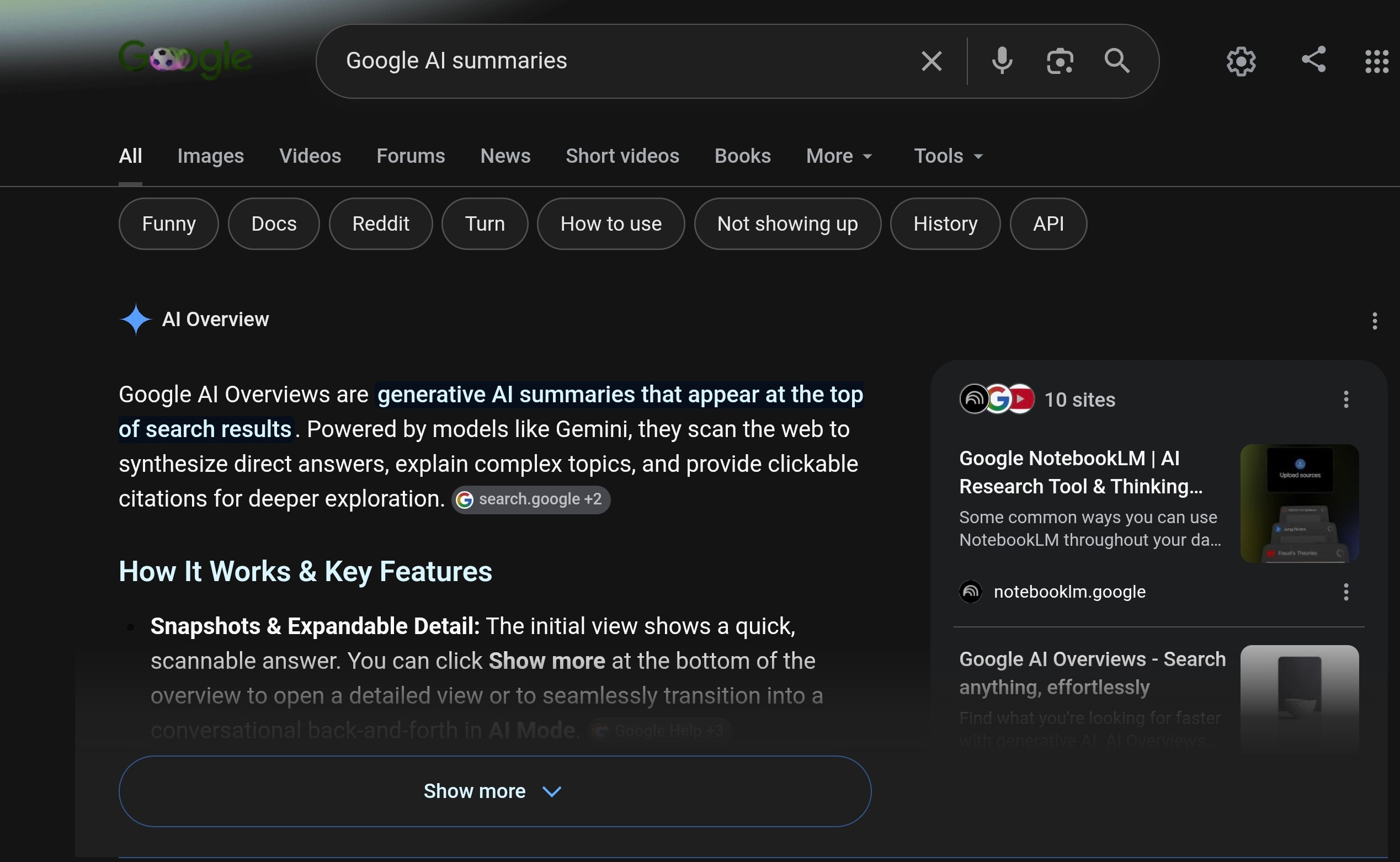
The screenshot that closes this dispatch illustrates the case plainly: a reader asks what AI summaries are, and the AI overview explains them while the cited material remains almost invisible, with the prominent links pointing back into Google's own properties rather than to the creators who wrote about the subject. It is a useful warning, not an accusation, and it deserves to be read as one. It's never wise to bite the hand that feeds you.
So let's ask a few practical questions to news organisations, regulators and informed readers alike. In an information economy where attention, data and capital concentrate around a small number of platforms, how is the value of journalism measured, and through which mechanism is it priced? Let us follow the signal from the question of authorship to the question of remuneration.
Chapter 1 — Authorship and the Duty to Disclose
17.1 — When the byline no longer guarantees the author
Sources
Germany's media shaken by AI scandal, DW
Editorial: Are you a simulation? AI and the art of the interview, Chemical & Engineering News (American Chemical Society)
New York City Council Candidate Is Accused of Forgery Over AI-Generated Posts, U.S. News
Dispatch
Germany's press absorbed two breaches of editorial trust this week. Tagesspiegel suspended its former publisher after he admitted composing opinion pieces with AI and not declaring it, and the Frankfurter Allgemeine withdrew a guest op-ed that had been written with similar assistance. A C&EN editorial describes how the problem reaches the source as well as the author: verification specialists now suggest a simple physical test for whether an interviewee is a generated avatar, a practical illustration of how far the question of identity has shifted.
The common thread is the integrity of attribution as a managerial control. A former New York council candidate has been charged with forgery for fabricating endorsements and a counterfeit news article with AI, including a manipulated image of a rival.
For news organisations the operational lesson is that trust is located in the disclosure rather than in the tool. As the C&EN piece observes, asking a counterpart to confirm they are human may become an ordinary part of professional contact rather than a sign of suspicion.
Reflections
• If readers expect to verify the human behind a byline, what assurance should news organisations really give to earn trust?
• Who should carry the burden of proof, and how is that burden best organized?
17.2 — The composition of the source pool
Sources
Revealed: ChatGPT draws more on GB News, Al Jazeera and Marie Claire than the BBC, IPPR analysis shows, IPPR
The British government wants to force more trustworthy news into your doomscrolling, Nieman Lab
Dispatch
An IPPR analysis finds that ChatGPT draws on a narrow range of outlets, citing The Guardian in 58 per cent of answers while the BBC is absent because it has exercised its opt-out. The think tank argues that AI assistants now perform an editorial function through the sources they include and omit, producing a new distribution of visibility among news brands.
Days later the UK government published a Green Paper proposing to make public service media more prominent in social feeds and search, with legislation held in reserve should platforms decline to cooperate voluntarily.
For policymakers the two items describe one question from opposite directions. The selection of which journalism a citizen encounters is made by systems whose operators describe themselves as neutral intermediaries. The British proposal answers that concentration of selection power with a public criterion of prominence, which raises its own governance question about who defines trustworthiness.
The underlying issue is that editorial influence has migrated to actors who do not present themselves as editors. Whether the curator is a model or a ministry, the legitimacy of ranking news for citizens is the matter at stake.
Reflections
• How far can a democratic government specify which news is prominent before promotion shades into endorsement?
• When the composition of the source pool changes without announcement, how should the public become aware of what was left out?
17.3 — The industrial supply of synthetic deception
Sources
Fact-checkers seek to stem a global tide of online scams, Poynter
Cyber based influence campaigns 15th - 21st June 2026 Report, Cyfluence Research
ARIAM: Disney, BBC, and the New York Times Form AI Content Coalition, AI Films Studio
Dispatch
The production of synthetic deception has reached industrial scale. Poynter reports fact-checkers contending with AI-cloned celebrities promoting fraudulent investment schemes, while Cyfluence's weekly review records deepfaked politicians, manipulated activist footage and more than 2,800 AI-generated deepfakes documented around the US midterm contests despite new disclosure statutes. The same review cites the Reuters Institute finding that news trust has fallen to 37 per cent and that weekly use of AI chatbots for news has risen to 10 per cent.
In response, established institutions are organising. Disney, the BBC, the New York Times, the Financial Times and others have launched ARIAM, a cross-sector alliance to set standards on training-data consent, attribution and synthetic-replica rights. News media start to treat AI governance as their own responsibility and have begun to draft the rulebook collectively.
Verification still depends substantially on human judgement. A coalition of brands is a meaningful contribution to that imbalance, and it operates alongside, rather than in place of, regulation and platform design.
Reflections
• If fabrications can be produced faster than they can be examined, how should we organize the newsroom of the future and maintain our DNA of trustworthiness?
• What would persuade platforms whose revenue rises with engagement to slow the circulation of the content that generates it?
Chapter 2 — Law in Search of Equilibrium
17.4 — A hundred actions, and the search for balance
Sources
NYT CEO confident in legal battles against OpenAI/Microsoft, Perplexity, Axios
Coalition of hundreds of local and regional newspapers sues OpenAI and Microsoft, InsiderNJ
Anthropic faces another copyright lawsuit, more than 100 authors say it used pirated books, India Today
Parallel litigation in 100-plus copyright suits v. AI companies produces litigation quagmire, resolution looks far off, ChatGPTisEatingTheWorld
Dispatch
Copyright disputes around AI have multiplied into a sustained body of litigation. The New York Times told Axios it remains confident in its actions against OpenAI, Microsoft and Perplexity, having committed around 20 million dollars over two and a half years, and a coalition of nearly 400 local and regional newspapers filed a further claim alleging systematic copying of their reporting.
A public tracker now counts 118 copyright actions against AI companies in the United States, with OpenAI named in 24, Meta in 14 and Anthropic in 10, even as more than 100 authors decline the Anthropic settlement in order to bring a separate claim.
Litigation and licensing operate as two halves of the same process: claims establish the legal boundaries, negotiated agreements establish workable prices, and a durable business model emerges from the interaction of the two.
This is how a developing market finds its footing. A thesis pressed in the courtroom and an antithesis negotiated at the licensing table together move the sector toward a synthesis, which is a settled and sustainable relationship between those who produce journalism and those who use it.
Reflections
• If litigation and licensing each supply part of the answer, how should a publisher sequence the two to reach a fair equilibrium?
• When a settlement in one case prompts fresh claims in another, what would a genuine resolution for the sector look like?
17.5 — The legal question of how data was obtained
Sources
How Strike 3 v. Meta Reframes AI Copyright Liability, Rain Intelligence
Belgian company sues Nvidia for training AI on its music catalog without permission, The Brussels Times
Dispatch
In Strike 3 Holdings v. Meta Platforms, the judge declined to dismiss the complaint and allowed it to proceed to discovery. The plaintiffs allege that IP addresses associated with Meta used BitTorrent between 2018 and 2025 to download their films thousands of times and to redistribute copies to other users. The court held that the reproduction and distribution involved in such downloading and uploading constitute an infringement under the Copyright Act in their own right, independently of whether the works were subsequently incorporated into any specific training set.
This reasoning introduces a brand new legal path. Rather than turning solely on what a model learned, a claim may rest on whether the underlying material was obtained lawfully, which is a separate and arguably more concrete question of evidence.
The Belgian company Winamp has filed in the United States, after a parallel action before the Ghent Commercial Court, over some 55,000 tracks from its catalogue said to have been used without authorisation, alleging copyright and contract violations together with unjust enrichment.
The development directs attention to provenance as a matter of legal record. Where the lawfulness of acquisition can be examined directly, the origin of the data becomes as material to the case as the behaviour of the model trained on it.
Reflections
• What incentive does a clean licensing route create once the manner of obtaining content carries independent legal weight?
• When the evidence consists of patterns of access rather than passages of text, which expertise can a court call on to assess it?
17.6 — Europe sets the framework
Sources
European Parliament and House of Lords publish reports on AI and copyright: policy directions for AI and copyright in the EU and the UK, Journal of Intellectual Property Law & Practice (Oxford University Press)
The Corner Newsletter: Our Next Revolution Conference on Capitol Hill & Europe's New Rules to Support Publishers in AI Era, Open Markets Institute
Swiss Parliament considers adding AI apps to media copyright bill, SWI swissinfo.ch
UK news industry backs law to stop deceptive AI scraping, Press Gazette
Here's What You Need to Know About Ottawa's New Policies on Social Media and AI, ChrisD.ca
Dispatch
European institutions are moving toward a licensing-first settlement. A comparative study finds the European Parliament and the UK House of Lords converging on a shared approach: maintain the opt-out under the CDSM Directive, strengthen transparency obligations, and cultivate a functioning licensing market rather than a broad exception.
Concrete measures are arriving alongside the principle. Open Markets reports Italy enforcing publishers' right to negotiate compensation, upheld by the Court of Justice, while the UK Competition and Markets Authority requires Google to let publishers opt out of AI summaries and model fine-tuning without consequent downranking, and to provide clear source attribution.
Switzerland is now considering whether to bring AI applications within the scope of its related-right copyright bill, which would oblige large online services to remunerate media companies for the use of their content, and the UK news industry supports a private member's bill requiring bots to identify themselves and their purpose.
The dynamics here are political as much as legal. French publishers, through the SNE, argue that lawmakers weakened a bill establishing a presumption of use under pressure to position France as a centre for AI, while Canada is advancing a broad set of digital-safety, privacy and deepfake rules expected to take full effect by 2028. The shared intention across jurisdictions is to make the use of journalism by AI both visible and remunerated, even where the pace of legislation differs.
Europe is constructing a framework in which access to journalistic content carries a price and a record. The question this raises is an economic one: whether content that is costly to produce can continue to be produced if its use generates no return, and on what terms that return should be set.
Reflections
• When licensing becomes the statutory norm, how is economic value determined when one party controls distribution and the other holds the content?
• How to enable a publisher to create value while avoiding that a dominant player can render this value commercially impractical?
Chapter 3 — Innovation: Building on Editorial Foundations
17.7 — Publishers and agencies build their own AI products
Sources
AFP and Mistral AI announce global partnership to enhance AI responses with reliable news content, AFP
VRT explores AI-driven conversational news formats, VNewsGuard Launches First AI Chatbot Built to Deliver Trusted Journalism Only from Reliable News Websites, NewsGuard
AI and the future of journalism: Balancing innovation and responsibility, European Science-Media Hub
Dispatch
Alongside the legal activity, several institutions are also building. AFP signed a multi-year partnership giving Mistral's assistant Le Chat access to its 2,300 daily stories in six languages, which AFP frames as both a diversification of revenue and a commitment to a European, verified-source approach.
VRT is developing conversational news grounded entirely in its own archive, allowing audiences to ask follow-up questions on subjects such as Ukraine and to receive answers drawn from VRT NWS journalism.
NewsGuard launched an assistant that responds only from 12,000 vetted publishers and commits to sharing revenue equally with the outlets it cites.
For news organisations this is innovation in the constructive sense. If audiences increasingly receive answers through conversational interfaces, there is clear strategic value in ensuring those answers originate in one's own journalism, carry one's own name, and generate a return. The European Science-Media Hub frames the discipline that should accompany this, namely a sustained attention to which systems are used, on whose data, and under whose accountability.
The opportunity is to move from being a source of raw material to being a recognised supplier of curated, attributable content. The accompanying consideration is the design of balanced relationships, in which a supplier maintains optionality across several partners and standards rather than depending entirely on one.
Reflections
• If your journalism informs another organisation's agents, what contractual terms keep the relationship a partnership of equals?
• When "trusted source" becomes a product attribute, who is qualified to certify reliability, and how is that certification kept accountable?
17.8 — Verification as a shared capability
Sources
Fake-o-Meter: Using AI to turn Confusing Claims into Clear Conversations, DW Innovation
No Data, No Party: Why Competition for High-Quality Journalism Matters in the GenAI Race, The Platform Law Blog
Dispatch
DW Innovation, the "Fake-o-Meter", running until 2029, aims to give ordinary users a conversational companion that examines images, video and audio and explains the context around a claim at the user's own pace.
The Platform Law Blog sets out the structural argument behind such efforts: high-quality, human-generated journalism is a third input in generative AI, alongside compute and talent, and access to it is a matter of competition policy as well as copyright.
For strategists the two pieces connect a practical tool to an economic thesis. Reliable content contributes materially to the accuracy and usefulness of models, which gives it genuine competitive value. The relevant advantage here is qualitative: specialised, verified and current reporting is distinctive precisely because it is difficult to produce, and that scarcity is what gives it bargaining weight regardless of the sheer volume of data a larger party may hold.
The constructive reading is that quality content is an asset whose worth will be recognised in the design of both markets and regulation. A healthy ecosystem rewards the production of distinctive journalism, which serves the interests of the developers who rely on it as much as the publishers who create it.
Reflections
• If quality journalism is a competitive input, how should it's valorisation be treated in competition and AI regulation?
• When distinctive, specialised reporting is a scarce resource, how do publishers best capture that value?
Chapter 4 — The Business Case: Google and the Economics of the Click
17.9 — The economics of the answered query
Sources
Google's AI Overviews are killing your organic clicks, Bright Labs
AI bots are reshaping the internet as human traffic loses dominance, Business Standard
Google AI changes could deal further blow to publisher Discover traffic, Press Gazette
Google's VP of Search tells CMOs: good SEO is still all you need for AI, ppc.land
Dispatch
The figures describe a measurable change in how value moves across search. Bright Labs, analysing more than 100 million keywords, reports organic clicks down over 60 per cent where AI Overviews appear, so that ranking first now yields roughly the traffic that ranking third produced before.
Cloudflare's data show bots generating 57.5 per cent of web requests, the first time automated traffic has exceeded human traffic, and Google's crawl-to-referral ratio moving from about two pages fetched per visitor sent to between fourteen and eighteen.
Press Gazette adds that Google has begun grouping publishers beneath AI summaries within Discover, a feed that has supplied a significant share of referral traffic for many newsrooms.
Against this, Google's VP of Search advises CMOs that sound foundational SEO remains sufficient, since AI Mode and AI Overviews operate on the same ranking systems.
For publishers the more nuanced reading is that optimising for a results page that increasingly resolves the query within itself produces diminishing referral returns, even as that same page may serve readers well.
The economic shift is that content continues to circulate while the associated referral traffic is redistributed. The relationship between content supplied and audience returned is being reset, and that reset is the substance of the business question facing publishers.
Reflections
• If a platform now captures the traffic that the source once did, how should a publisher reevaluate the relationship with such a platform?
• How long can a strategy built on referral remain viable when the results page increasingly answers the query in place?
17.10 — Google revises the terms of licensing
Sources
Google strikes tough negotiating stance with publishers over AI licensing, The Information
Google Looks To Reportedly Broaden Publisher Licensing Deals, MediaPost
Google launches initiatives to help Malaysian newsrooms navigate AI, changing audience habits, Malay Mail
Dispatch
As the value of the referral changes, Google is revising the terms on which it licenses content. The Information reports a firm negotiating position, under which broader licences, including consent to use content for model training, are presented as the condition for participating in the News AI pilot, while publishers who decline are told they will lose the payments previously made under the Showcase programme, which Google intends to wind down.
MediaPost adds that these comprehensive agreements consolidate legal and operational advantages for Google, and quotes an executive who notes that low referral volumes have led some publishers to develop direct subscriber and registration relationships.
In Malaysia, Google has launched Project Sigma 2.0 and Project Berita to help newsrooms adapt to AI and changing audience habits through training and tooling.
For news leaders the structural feature is that one party occupies several roles at once: it shapes discovery, sets the licensing terms, administers the legacy payments, and funds the capacity-building programmes. That concentration of roles is the analytical point, and it warrants careful contractual attention rather than indignation. It's worth recognising that a platform of this scale carries a corresponding responsibility, and that the largest gateway is the one best placed to set a constructive example.
The pivot some publishers are making toward direct subscriber relationships is best read as a calculated strategic choice rather than a retreat. Building owned audiences, first-party data and recurring revenue is a basic economic response to a changing distribution environment and a source of resilience in its own right.
Reflections
• If one party shapes discovery, licensing and training terms together, how should a publisher structure the agreement to preserve the balance?
• When the largest gateway also offers to help newsrooms adapt, how is it ensured that "navigating AI" serves the publisher's interest as well as the platform's?
Conclusion
The question of authorship concerns who may speak in a newsroom's name; the question of law concerns who may use its work and on what terms; the question of innovation concerns whether publishers can supply AI systems rather than merely feed them; and the question of economics concerns how value is shared once readers receive their answers on the results page.
Each leads back to the gateway between audiences and journalism, where attention, data and capital concentrate around a small number of platforms. Google occupies much of that gateway, and with that position comes a responsibility including the expectation that it sets a constructive example.
The screenshot that anchors this dispatch illustrates the point. A reader asks Google what AI summaries are, and the AI overview supplies the explanation while the cited material remains invisible and the prominent links lead back into Google's own services.
It is a clear illustration of the question at the center of this new economy.
The constructive path runs through synthesis. A sustainable future for journalism and for AI alike will be based on the premise of an equilibrium.
Let's be straightforward: quality journalism is scarce, costly to produce and valuable to those who use it, and a durable market is one that prices it accordingly.
The central question of Dispatch 17 is not who wins, but how the parties reach an equilibrium that keeps quality journalism worth producing.